
Blog
Databricks with Iceberg

Unlock Data Engineering Careers with DataBricks & Iceberg
Discover how DataBricks and Iceberg drive innovation in data engineering and boost your career prospects in the GenAi landscape.
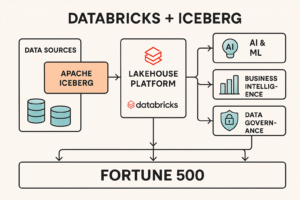
Fortune 500 enterprises are rapidly adopting the Databricks + Apache Iceberg stack because it solves critical problems of scale, governance, interoperability, and AI-readiness that legacy data lakes and warehouses can’t handle.
1. Open Table Format Standardization
-
Apache Iceberg has emerged as the de facto open standard for tabular data in the data lakehouse.
-
Unlike legacy Hive tables, Iceberg supports schema evolution, hidden partitioning, and time travel without complex rewrites.
-
This means enterprises can unify streaming + batch pipelines under one open, vendor-neutral standard.
👉 Why it matters: Fortune 500s avoid vendor lock-in while ensuring future-proof compatibility across Spark, Flink, Trino, Presto, and Snowflake.
2. AI & ML at Scale with Databricks
-
Databricks provides a lakehouse architecture that natively integrates BI and AI/ML.
-
With Iceberg tables, organizations can train LLMs and ML models directly on governed, fresh, and reliable data without duplicating it into a warehouse.
-
Features like Unity Catalog add fine-grained governance, lineage, and data sharing, crucial for regulated industries.
👉 Why it matters: Large enterprises can move faster with AI while staying compliant.
Join our Extensive Program on Data Engineering with GenAi @ Times Analytics
3. Cost Optimization & Performance
-
Iceberg’s efficient file pruning and metadata layers mean faster queries and lower compute costs than legacy data lakes.
-
Databricks’ Photon engine + Iceberg indexing delivers sub-second BI queries at warehouse-level performance — without paying warehouse-level costs.
👉 Why it matters: At Fortune 500 scale, billions of rows = millions in cost savings.
Join our Extensive Program on Data Engineering with GenAi @ Times Analytics
4. Seamless Multi-Cloud & Data Sharing
-
Iceberg enables cross-platform table sharing: data written once in Iceberg can be read in Snowflake, BigQuery, Athena, Presto, or Databricks.
-
Fortune 500s with hybrid/multi-cloud strategies gain flexibility to integrate acquisitions, partners, and subsidiaries.
-
Databricks’ Delta-to-Iceberg interoperability allows gradual migration without downtime.
👉 Why it matters: Enterprises avoid data silos and maintain agility during mergers and digital transformation.
Join our Extensive Program on Data Engineering with GenAi @ Times Analytics
5. Governance & Compliance at Enterprise Scale
-
Fortune 500s operate under strict regulatory regimes (HIPAA, GDPR, SOX).
-
Iceberg + Databricks provides ACID compliance, data versioning, audit logs, and lineage tracking.
-
This supports risk management, explainable AI, and data democratization without sacrificing control.
👉 Why it matters: Data leaders can say “yes” to innovation while staying compliant.
Join our Extensive Program on Data Engineering with GenAi @ Times Analytics
Fortune 500s are betting on Databricks + Iceberg because it gives them:
✅ Open standard interoperability (no lock-in)
✅ AI/ML readiness at scale
✅ Lower costs with high performance
✅ Multi-cloud flexibility
✅ Enterprise-grade governance
Join our Extensive Program on Data Engineering with GenAi @ Times Analytics
At Times Analytics we prepare you with a Curriculum that prepares you to thrive in the Industry as an Expert Big Data Engineer.
In Our Course on Data Engineering with GenAi
Topics You will Master
-
Data engineering course
-
Data pipeline development
-
Big data architecture
-
Learn data engineering online
-
Real-time data processing
-
Data engineer training
What are you waiting for Join our Course Now and Grab a Offer .


